

最近在捣鼓 text-to-speech 和 voice-conversion。整个发展史我不是很清楚,所以就写点现有的吧。
二阶段模型 (Two-Stage)
Tacotron2
我一开始接触到的 TTS 应该是 Nvidia 的 Tacotron2。它把文本通过转换生成梅尔频谱 (Mel-Spectrum),然后用 WaveNet 模型把梅尔频谱还原为音频。
音频作为和时间相关的数据也是存在频域和时域的,可以把音频信号和频谱之间相互转换。梅尔频谱则是基于人类耳朵“对低频敏感”的特征将频率尺度改变,让低频区域拉伸占比大一些罢了。
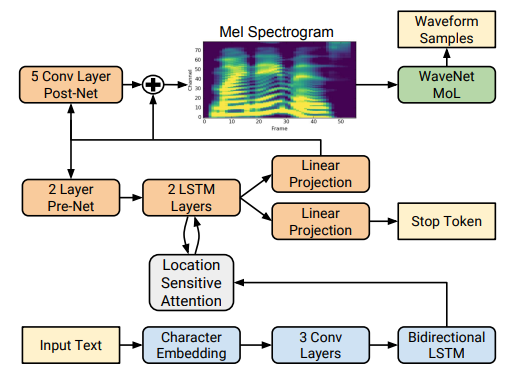
这个 Tacotron2 广泛采用了 LSTM 对文本和语音进行建模并且用卷积提取特征。输入首先是被 LSTM 分析过后接下来被投喂到另一个 LSTM 里面,第二个 LSTM 负责生成梅尔频谱。和文本自回归预测一样它也通过 Stop Token 来停止生成。
WaveNet 则是一个典型的自回归模型,也就是根据之前的数据预测下一个。这和 Encoder-Only Tranformer 是一样的。
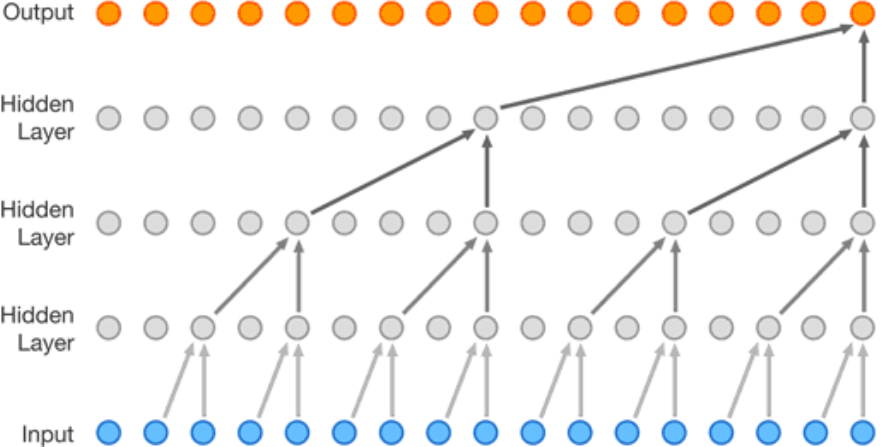
如图所示,WaveNet 就是一群卷积神经网络组成的预测模型,通过历史数据预测下一个点。
其实图像生成界在GAN的出现之前,也广泛采用了自回归模型生成图片,例如 PixelRNN and PixelCNN。
在实际使用过程中这个 WaveNet 被替换为了 HiFiGAN 之类的声码器 (Vocoder) ,不过其实它们是同一类的。大量卷积来操作音频时域。
HiFiGAN 在还原高质量音频上采用了 Adversarial Training,也就是额外引入一个判别器来对真假样本进行判断。这个判别器还不是一般的判别器,它叫做多周期判别器 (Multi-Period Discriminator)。其实也就是接受不同周期大小的判别器组合在一起,从多个角度进行判断。除了多周期判别器还有多尺度判别器 (Multi-Scale Discriminator),也就是在不同经过平均处理的音频上进行判断。
DiffSinger
毕竟在图像生成上这个 Diffusion 模型可是大放异彩,就有人会把它搬到别的领域。DiffSinger就做的还不错。
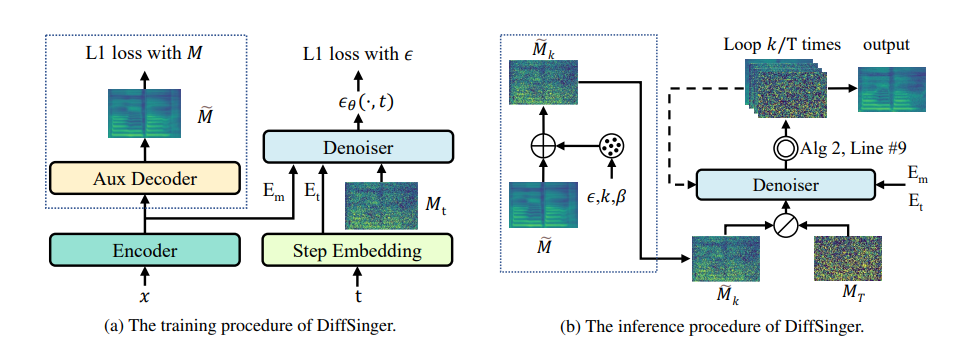
大概就是采用了浅扩散,通过condition数据进行扩散采样生成梅尔频谱。
浅扩散看来就是从扩散的一半进行,不过我也没细看。
端到端模型 (End-to-End)
然后我就看了 VITS,这个模型看起来要复杂一点点,不过也很容易理解。
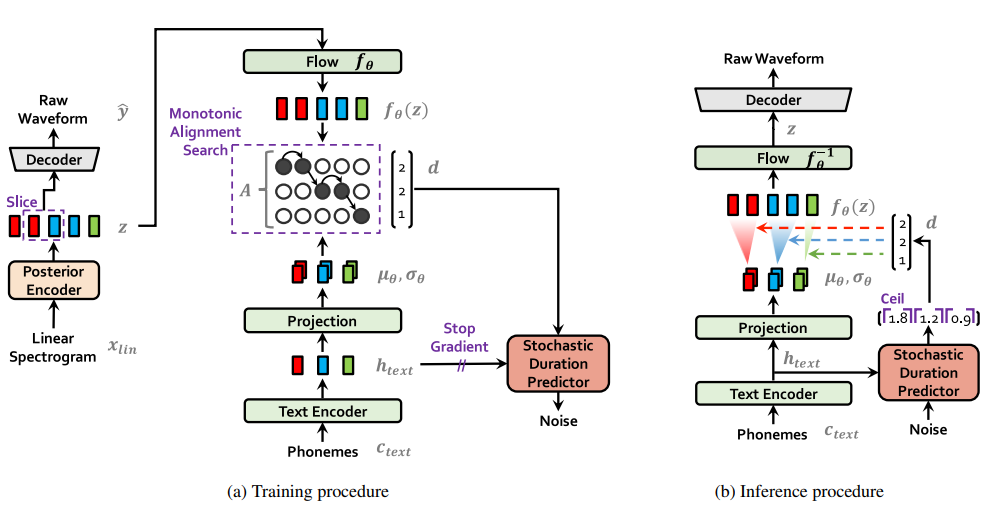
端到端的意思就是,它不需要声码器来把 Mel-Spectro 转换为 Raw Waveform,它直接生成音频的 Waveform。
从最左边看到,它其实是构造了一个 VAE (Variational AutoEncoder) 用来学习音频的潜空间。这下模型不需要在 Mel-Spectro 上进行学习了,而是可以直接学习这个它自己的音频表达。VAE的原理我之前讲过了。我发现近期表现优异的模型都会自行学习潜空间,可能这就是潜空间的天然优势吧。
Anyway,这个 VAE 的构造也是很简单。编码器是一堆卷积,解码器是一堆反卷积。编码器输入是线性的音频频谱,而解码器直接输出音频波形。这里的解码器它把 HiFiGAN 的模型搬了过来,并且同样把 GAN 的判别器搬了过来,但是它只采纳了多周期判别器,没有多尺度。所以这玩意应该叫做 VAE-GAN 模型。GAN 可以让它生成高质量的音频。
那么 VITS 具体是如何把文本和音频关联起来的呢?这里它用了很巧妙的两个 Trick,第一是用 Flow-based 模型对文本和音频的两个不同的分布进行映射,第二则是采用了周期预测 (Duration Predictor) 将文本和音频长度挂钩。
我们都知道这个卷积下来的音频嵌入潜空间的长度是和音频长度正相关的,也就是这条音频嵌入有多长这个音频就有多长,那么文本下来的文本嵌入长度和文本也是相关的。这就导致我们不能直接把文本的空间映射到音频空间,因为它俩最后长度可能就不一样。
这时候 VITS 引入了 Stochastic Duration Predictor,这个东西会把文本当参考,预测出每个音节在发音里的长度,然后让音节进行拷贝变长。这样一个音节可能就对应好几个音频的嵌入。
Flow 模型是可逆的,意味着我们可以让两个分布通过它进行互相转换。在训练时候,后验音频嵌入被映射到文本这里用来做 MAS 也就是长度的匹配,而在推理时候就反过来将文本空间转成音频空间。
效果挺好的,就和套了 VAE 的 Lantent Diffusion 一样,所以我们可以看到,套个 VAE 就是无敌的存在了(
声音转换模型
声音转换比文本简单,因为是单模态进行操作的,按照相同的窗口大小,输入输出长度也就相同,所以不需要长度转换。
一些感想
本质上来说,在神经网络里我们面临的就是不同分布和采样的转换。如何让模型高效的学习到分布才是最终的问题。
毕竟是模型,终归都是现实世界的映射和建模,那么引入现实世界的分布就不可避免,比如图像,音频,文本。但是再怎么降低分辨率(比如梅尔频谱),模型都不好直接学习。最好的办法同样是想办法将其放置到模型自己学习到的潜空间里,使用各种 Encoder 和 Decoder 来做到。
接下来在多模态融合的地方,比如文本和音频,就可以再用一个分布转换模型来进行转换,比如一个 Transformer 或者一个 Flow。
列出我们现在拥有的工具:
- GAN 模型 Adversarial Learning: 可以学习到比较高质量的低维度分布到高维度分布的映射,因为模型可以自己改进。但是比较难控制学习过程。
- Flow 模型: 可以学习到简单到复杂分布的映射,并且可以逆向进行映射。坏处就是可以用的地方很局限。
- VAE 模型: 可以学习到高维分布映射到低维,和低维度映射到高维的两个转换。就是训练起来太难,毕竟模型和人一样慵懒。
- Diffusion 模型: 可以学习到简单低维到复杂高维的映射,并且因为模型可以感受到细致的东西所以重建的能力很强,可以有创造性。就是训练和推理比较费劲。
- 对比学习 Contrastive Learning: 把 Loss 设置为两个模型输出的差值,那么就可以尽可能让两个模型的输出靠在一起,实现多模态的融合。比如 CLIP
反正我还没学那么深的统计学和数学,创造不了积木,那就用现成的积木拼装呗